

It seems like every week there’s a new AI tool that promises to change everything. The hype is impossible to ignore. But behind the marketing, what are we actually dealing with? How do Large Language Models (LLMs) really work, and more importantly, what are the practical limitations that we, as developers, QAs, and analysts, need to understand to use them effectively and responsibly?
This article cuts through the noise to explain the core mechanics of Generative AI. We'll explore how these models "think," where they fail, and provide a set of practical heuristics for applying them in our work.
The 'Before' State: From Hard-Coded Rules to Learned Patterns
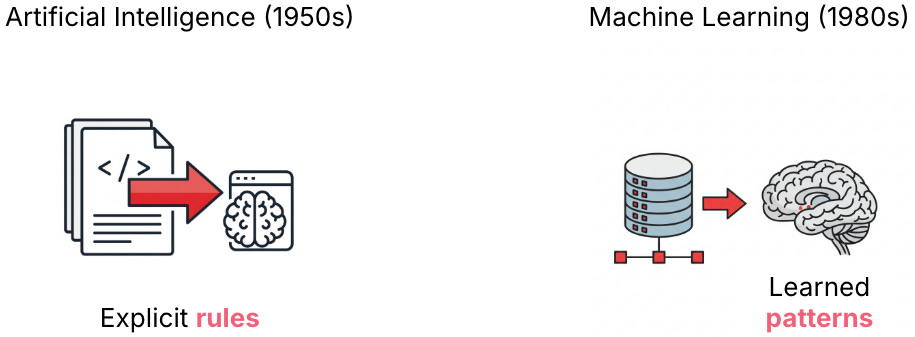
To understand today's Generative AI, we have to look at its conceptual ancestors. The original dream of Artificial Intelligence (beginning in the 1950s) was about logic and explicit rules. The idea was to encode expert knowledge into a series of IF <condition> THEN <action> statements. This approach is far from obsolete; it’s still the backbone of many complex systems.
For example, I previously worked on a phishing detection team at a global cybersecurity company, where our core detection engine was a sophisticated, rule-based AI. We analyzed an email’s characteristics, and if the combined weighted score of all rules triggered a threshold, we marked it as malicious. That was our production system.
The first major evolution of this paradigm was Machine Learning (ML), which gained traction in the 1980s. Instead of engineers hand-crafting every rule, we could feed a system massive amounts of data and let it discover the patterns on its own. We don't tell a spam filter every possible suspicious word; we show it thousands of examples, and it learns the statistical characteristics of spam. These two ideas—rules and learning—are often used together. Our plan at the cybersecurity company was to layer ML on top of our rule engine to automatically spot new threats, rather than waiting for an engineer to write a new rule.
Introducing the Core Concept: Generative AI
The next leap came with Deep Learning in the 2010s, a type of ML that uses complex, multi-layered "neural networks" to find incredibly subtle patterns in data. This is the technology that powered the huge advances we saw in image recognition and speech-to-text.
That brings us to today's breakthrough: Generative AI.
What is it? Generative AI takes powerful Deep Learning models and flips their function. Instead of just recognizing patterns (e.g., "this image contains a cat"), it uses its understanding of those patterns to create new, original content (e.g., "generate a picture of a cat"). Large Language Models are a prime example of this capability.
Why does it matter? The impact is massive because an estimated 80% of the world's data is unstructured text—emails, documents, support tickets, etc. LLMs are the first technology that can both process and generate human language at scale, creating a new human-computer interface where we can use natural language to express intent.
How does it work? At its core, an LLM is a sophisticated pattern-matching machine built on a technology called the Transformer architecture. Its fundamental job is surprisingly simple: to predict the most statistically probable next word in a sequence. It's essentially a very powerful autocomplete. To do this, it relies on two key concepts:
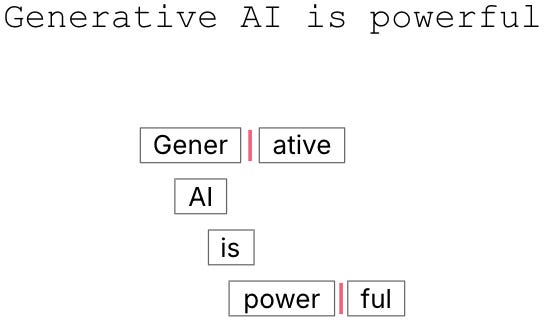
Tokens: The model doesn't see words; it sees "tokens". Text is broken down into these building blocks—which can be words, parts of words, or punctuation. For example,
Generative AI is powerfulmight become["Gener", "ative", " AI", " is", " powerful"]. A model's limits and API costs are all measured in tokens.The Context Window: This is the model's short-term memory. LLMs are stateless; they don't truly "remember" past conversations. With each prompt, the application sends the entire conversation history back to the model. This entire block of text must fit within the context window, which has a fixed token limit (e.g., 8k or 128k). If a conversation gets too long, the oldest messages are dropped, which is why the model seems to "forget" what was said earlier.
Practical Applications: Choosing the Right Tool for the Job
Different LLMs are trained with different goals, giving them unique strengths. Choosing the right one is a key engineering decision. The following list is not exhaustive, but it reflects the tools my team and I rely on for our daily work.
The main model families you'll encounter are:
OpenAI's GPT Series (
GPT-4o, etc.): Best known as a powerful all-rounder, excelling at tasks requiring strong logical reasoning and complex code generation. This is often the go-to for debugging a tricky algorithm or scaffolding a new service.Anthropic's Claude Series (
Claude 3.5 Sonnet, etc.): Built with a heavy emphasis on safety and "Constitutional AI". Claude often produces more careful, nuanced writing and is a great choice for tasks like drafting detailed technical documentation or analyzing sensitive user feedback where tone and safety are paramount.Google's Gemini Series (
Gemini 1.5 Pro & Flash): This family offers a trade-off. Gemini Pro is the high-power version focused on top-tier reasoning and advanced multi-modal capabilities. Its sibling, Gemini Flash, is optimized for speed and cost-efficiency, making it ideal for high-volume, lower-complexity tasks like chatbots or data extraction where low latency is critical.

Common Pitfalls & Misconceptions
The architecture of LLMs leads to two fundamental limitations that every user must understand.
1. Hallucinations: Plausible vs. Truthful
Because an LLM's only job is to predict the next most probable token, it is optimized to generate text that is plausible, not text that is factually true. It has no internal knowledge base or concept of truth. If you ask it to find sources for a claim, it will generate a list of references that looks perfect—with authors, titles, and journals that fit the pattern—but the sources themselves may be completely fabricated.
How to avoid it: Be professionally skeptical. Treat all outputs as a first draft. Always verify facts, test all code, and check any sources it provides.
2. The Black Box Problem: Why vs. What
We can make an LLM's output deterministic by setting a parameter called "temperature" to zero, meaning it will give the same output for the same input every time. So we can see what it did. However, we can't see why it chose one token over another in a way that is humanly understandable. The decision is a result of calculations across billions of parameters, not a logical decision tree we can audit.
Why it matters: This makes it nearly impossible to debug why a model gives a strange answer. In high-stakes domains like finance or healthcare, it's difficult to trust a system when there is no transparent reasoning path.
Core Trade-offs: Free vs. Paid Models
The difference between free and paid AI tools is not just about features; it's about the entire engine. The primary trade-off is cost vs. capability.
Underlying Model: Free tiers typically use older, smaller, and less powerful models. Paid tiers give you access to the flagship models.
Context Window: Paid models have much larger context windows (e.g., 128k+ tokens vs. 4k-16k), allowing you to work with larger documents and maintain longer conversations.
Reasoning Ability: Premium models are significantly better at following complex, multi-step instructions. Less capable models are more prone to "laziness"—giving simplified answers, writing placeholder code, or telling you to do it yourself.
For simple tasks, a free model may suffice. For complex development work, the limitations of a less capable model can become a significant bottleneck.
Conclusion: 4 Heuristics for Using AI Responsibly
Generative AI is a powerful tool, not magic. Understanding its mechanism—next-token prediction within a limited context window—is key to using it well. To ensure we are using these tools in a safe, effective, and responsible way, our team should always ask four questions before starting a task:
Do we have permission? Is the use of AI approved for this task by both the client and our company's policies? This is a non-negotiable first step.
Are we exposing sensitive data? Does the prompt contain any client secrets, personal information, or confidential data? The answer must be no.
How will we verify the output? What is our strategy for human review and testing? Whether it's a peer code review or a QA testing plan, a verification process is essential.
Is this the right tool for the job? Is the model's speed, cost, and capability a good fit for this task? This is about making a deliberate engineering trade-off.
By embracing professional skepticism and applying these simple heuristics, we can move beyond the hype and begin using Generative AI as what it is: a powerful, imperfect, but profoundly useful new tool in our professional toolkit.